idml2xml: Verbesserungen
bei geschachtelten Formaten
Gerrit Imsieke, transpect user Group 2023
Geschachtelte Formate
(nested styles)
- Besonderheit von InDesign
- Damit kann man festlegen, dass z.B. das erste Wort eines Absatzes oder alles bis zum ersten Halbgeviert ein anderes Zeichenformat erhält
- Außerdem werden im gleichen Einstellungsdialog Initialen definiert
- Setzer:innen nutzen geschachtelte Formate gerne
- Lässt sich aber weder in Word noch in EPUB/HTML noch in unserem Hub-XML abbilden
- Deswegen machen wir die Zeichenformatzuweisungen in den entspr. Absätzen explizit
idml2xml
- Makroskopischer Konvertierungsschritt von transpect
- Konvertiert in mehreren XSLT-Durchläufen den IDML-XML-Inhalt nach Hub-XML (erweitertes DocBook)
- Liegen im IDML geschachtelte Formate vor, waren es bisher 22 XSLT-Durchläufe; liegen keine vor, sind es 18
- Die Behandlung geschachteler Formate hatte Defizite, z.B., wenn Initialen und explizite Zeichenformatzuweisungen zusammenfielen
- Diese Defizite gab es sowohl in Bezug auf die Korrektheit der Resultate als auch in Bezug auf die Performanz
- Die Defizite wurden in zwei Schritten (Verbesserung der Initial-Auswertung und Verbesserung bei den übrigen Instruktionen) behoben
Beispieldatei
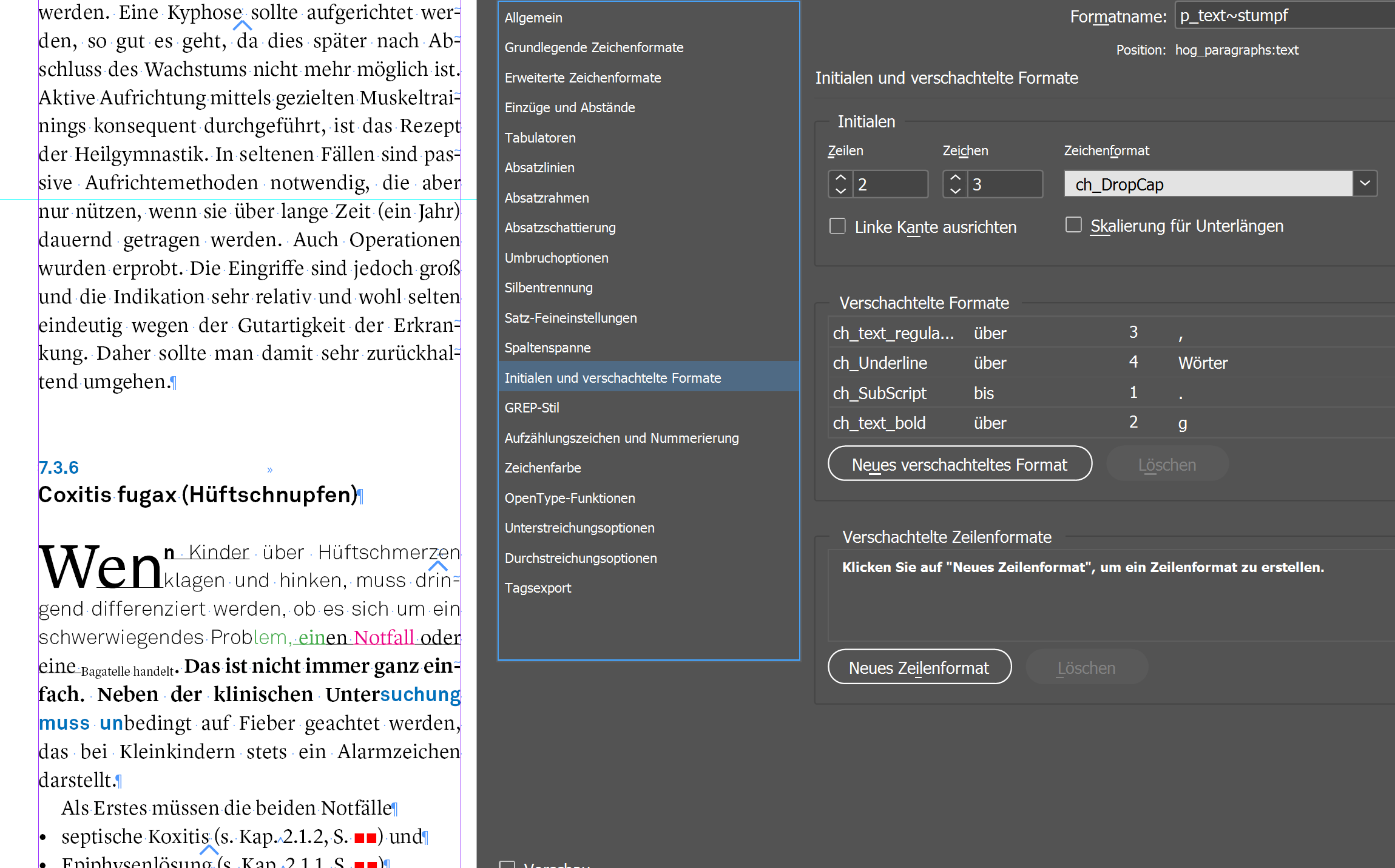
Modifizierte Datei aus dem Testset von Hogrefe Bern
Zustand vorher und xsl:accumulator-Verbesserungen
| Bis August 2023 | Seit 7.8.2023 (nur Initialen) | Seit 10.11.2023 (Rest) | |
|---|---|---|---|
| XSLT-Durchläufe* | 22 | 22 | 20 |
| Laufzeit* | 68 min** | 7 min | 1:30 min |
| Darstellung im EPUB*** | 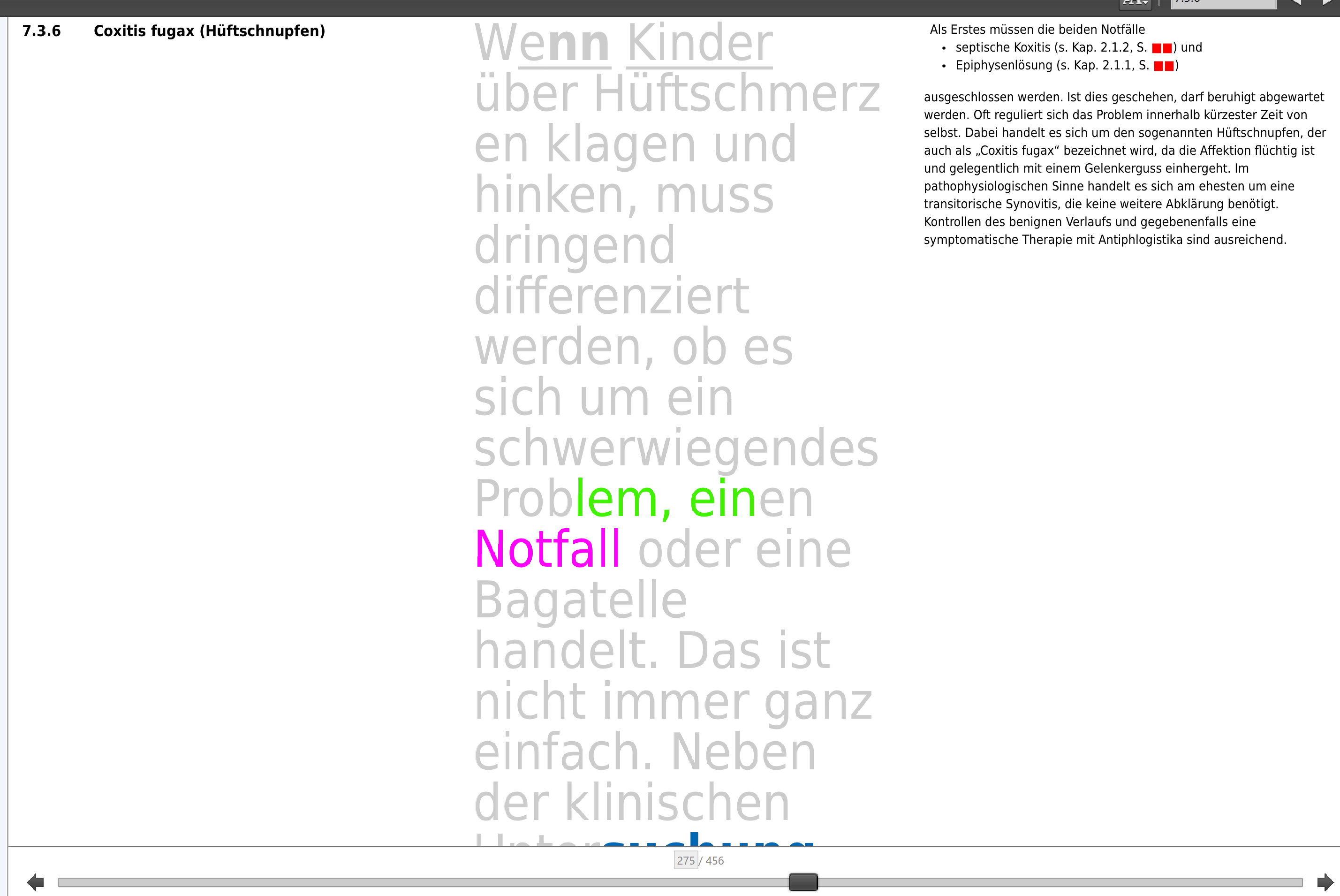 |
 |
 |
* nur idml2xml, nicht der gesamte Konvertierungs- und Prüfprozess
** die sehr lange Laufzeit trat nur bei komplexen Nested Styles auf
*** das offensichtlich falsche Ergebnis trat bei Überlappung von Initialen und explizit zugewiesenem ZF auf
Anlass
Anfang August, quasi gleichzeitig:
- Suhrkamp-Ticket zu fehlerhafter Verarbeitung von geschachtelten Formaten

- Balisage-Beitrag zu XSLT-Akkumulatoren
Altes Verfahren
Bisher lief die Verarbeitung geschachtelter Formate in 4 Schritten:
- Split-Punkt-Kandidaten ermitteln (Zeichenpositionen in Textknoten, bis zu denen ein ZF angewandt werden könnte – z.B. alle Tabs oder alle Doppelpunkte, falls die Instruktion sagt, bis zum 3. Doppelpunkt ZF XY anzuwenden)
- Diese Kandidaten aus eventuell umgebendem Markup (explizite Formatzuweisungen, Tiefstellungen, Links, …) herausziehen, so dass sie unmittelbar unter dem Absatz-Element stehen
- Ggf. neues ZF-Tagging einbringen (z.B. bis zum 3. Doppelpunkt-Split-Kandidaten alles in einen
spanmit ZF XY packen - Bereiche mit gleichem ZF wieder zusammenführen, dabei auch die ungenutzten Split-Kandidaten mit einschließen
Defizite:
- Die Splitpunkt-Kandidaten für Initialen, für String-Separatoren wie Doppelpunkt und Halbgeviert oder auch für Instruktionen wie „ZF auf die ersten 2 Wörter anwenden“ werden per Regex (aus den Instruktionen generiert) identifiziert
- Die Regexes werden allerdings nur innerhalb von Textknoten angewandt. Bei vorhandenem Markup innerhalb eines Absatzes – explizit zugewiesene Formatvorlagen oder Ad-hoc-Formatierung, Tiefstellungen, Links oder eingestreuten Indexbegriffen und Fußnoten – muss eigentlich Text mitanalysiert werden, der sich über Markupgrenzen erstreckt bzw. der Indexbegriffe oder Fußnotentext ignoriert. Andernfalls werden Splitpunktkandidaten nicht oder falsch ermittelt
- Der 2. Schritt (Splitpunktkandidaten hochziehen) kann bei komplexen Instruktionen / langen Texten lange dauern
Sowohl beim Suhrkamp-Problem als auch beim Hogrefe-Problem konnten die regulären Ausdrücke wegen vorhandenen Markups keinen Splitpunkt-Kandidaten finden, weswegen im Konvertierungsergebnis bei Suhrkamp der ganze Absatz fett war und bei Hogrefe der ganze Absatz aus Initialen bestand.
Das Suhrkamp-Problem konnte die Kollegin Schmalfuß lösen, indem sie Zeichenbereiche mit dem speziellen ZF
No character style auflöste.
Für eine allgemeine Lösung muss man wie gesagt im vorliegenden Textknoten die Inhalte anderer Textknoten desselben Absatzes berücksichtigen.
Hypothetische exaktere XSLT-2-Lösung
Mit herkömmlichem XSLT 2.0 würde man in jedem Textknoten neu ermitteln, wie der Text davor lautete, ob er mit einer Wortgrenze endet oder ob das Wort im nächsten Textknoten weitergeht und wie viel des vorangegangenen Textes durch die aktuelle Instruktion bereits verbraucht ist. Zunächst müsste man ermitteln, welche Instruktionen schon abgearbeitet wurden. Man muss also für jeden Textknoten die komplette Analyse des Absatzes (bis einschl. diesem Textknoten) von vorne durchführen.
Das wäre ähnlich ineffizient wie das Hochziehen der Splitpunktkandidaten, das im Hogrefe-Fall ca. 67 der 68 Minuten gebraucht hat
XSLT 3: Akkumulatoren
Normalerweise hat man bei XSLT während der Verarbeitung keinen Zugriff auf das bisherige Verarbeitungsergebnis. Aus diesem Grund laufen komplexere Verarbeitungen oft in mehreren Durchläufen, in denen Zwischenergebnisse im transformierten Dokument gespeichert werden, z.B. bei welcher Zeichenposition innerhalb des Absatzes ein Textknoten beginnt.
Die xsl:accumulator-Instruktion bietet genau diesen Zugriff während der Verarbeitung: Man
kann mitzählen, bei welcher Zeichenposition man ist, man kann aber auch komplexere Strukturen wie die
aktuell aktive NestedStyle-Instruktion und den noch nicht von bisherigen Instruktionen abgedeckten
markup-unabhängigen Text mitführen und -berechnen.
Zu diesem Zweck kann man sich beliebige Akkumulatoren definieren, indem man ihnen einen Namen gibt und die Berechnungsvorschriften dafür spezifiziert, wie der Wert des Akkumulators sich ändert, wenn während der Dokumentverarbeitung ein Knoten betreten bzw. verlassen wird.
Das bietet drei Vorteile:
- „Korrektere“ und unaufwändige Berechnung der Position von Splitpunkt-Kandidaten
- Der Absatz muss nicht zerhackt werden, damit jeder Splitpunkt-Kandidat unmittelbar unterhalb des Absatzes liegt, sondern es genügt, z.B. nur den 3. Doppelpunkt im Textknoten, in dem der 3. Doppelpunkt steht, mit einem Tag zu umgeben.
- Dann muss man auch nicht mehr die zerhackten Absatzbestandteile zusammenführen.
Für die beiden letzten Punkte gäbe es auch Möglichkeiten, sie mit XSLT 2 ohne Zerhacken des Absatzes zu gestalten. Der erste Punkt aber bleibt, und diese unaufwändige und textknotenübergreifende Methode, in einem Durchlauf die Kandidaten zu ermitteln und nur die tatsächlich wirksamen (z.B. 3. Doppelpunkt) zu taggen, geht in XSLT nur mit Akkumulatoren.

Der Akkumulator nested-style-instruction (Ausschnitt)
Fazit
- Die Einführung von
xsl:accumulatorzunächst nur für die Verbesserung der Initialenbehandlung brachte erhebliche Verbesserungen bei Laufzeit und Konvertierungsergebnissen beim Aufeinandertreffen von Initialen mit Textknoten in Markup (z.B. explizit zugewiesenes Zeichenformat) - Die Einführung von
xsl:accumulatorfür die übrigen NestedStyle-Instruktionen brachte weitere Laufzeitverbesserungen, außerdem leicht verbesserte Präzision beim Anwenden der Zeichenformate - Dabei konnten zwei XSLT-Durchläufe eingespart werden